环境:centos7+hadoop3.0.3+hbase2.0.1+jdk8
简介
什么是HBase
HBASE是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBASE技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBASE的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。
HBASE是Google Bigtable的开源实现,但是也有很多不同之处。比如:Google Bigtable利用GFS作为其文件存储系统,HBASE利用Hadoop HDFS作为其文件存储系统;Google运行MAPREDUCE来处理Bigtable中的海量数据,HBASE同样利用Hadoop MapReduce来处理HBASE中的海量数据;Google Bigtable利用Chubby作为协同服务,HBASE利用Zookeeper作为对应。
Hbase的优点
- 线性扩展,随着数据量增多可以通过节点扩展进行支撑
- 数据存储在hdfs上,备份机制健全
- 通过zookeeper协调查找数据,访问速度快
HBase集群中的角色
- 一个或多个主节点:HMaster
- 多个从节点:HRegionServer
安装HBase(单机)
- 添加用户hbase
useradd hbase
passwd hbase - 配置sudo免密
在root用户下
vi /etc/sudoers
在
root ALL=(ALL) ALL
下面添加
hbase ALL=(ALL) ALL
注:修改完退出root用户,登录hbase用户 - 创建目录
mkdir /home/hbase/apps/ - 上传并解压安装包hbase-2.0.1-bin.tar.gz
tar -zxvf hbase-2.0.1-bin.tar.gz -C /home/hbase/apps/ - 配置环境变量
vi ~/.bash_profile
添加
export JAVA_HOME=/usr/local/jdk
export HBASE_HOME=/home/hbase/apps/hbase-2.0.1
export PATH=$PATH:$JAVA_HOME/bin:$HBASE_HOME/bin
更新配置
source ~/.bash_profile - 修改配置文件hbase-env.sh
vi /home/hbase/apps/hbase-2.0.1/conf/hbase-env.sh
在28行注释的JAVA_HOME下添加
export JAVA_HOME=/usr/local/jdk
export HBASE_MANAGES_ZK=true
export HBASE_LOG_DIR=/home/hbase/logs 修改配置文件hbase-site.xml
vi /home/hbase/apps/hbase-2.0.1/conf/hbase-site.xml
在<configuration>标签添加123456789101112<property><name>hbase.rootdir</name><value>file:///home/hbase/hbase_data</value></property><property><name>hbase.zookeeper.property.dataDir</name><value>/home/hbase/zookeeper</value></property><property><name>hbase.unsafe.stream.capability.enforce</name><value>false</value></property>启动hbase
start-hbase.sh- 进入hbase命令行
hbase shell - 页面监控
http://hadoop5:16010
HBase数据模型
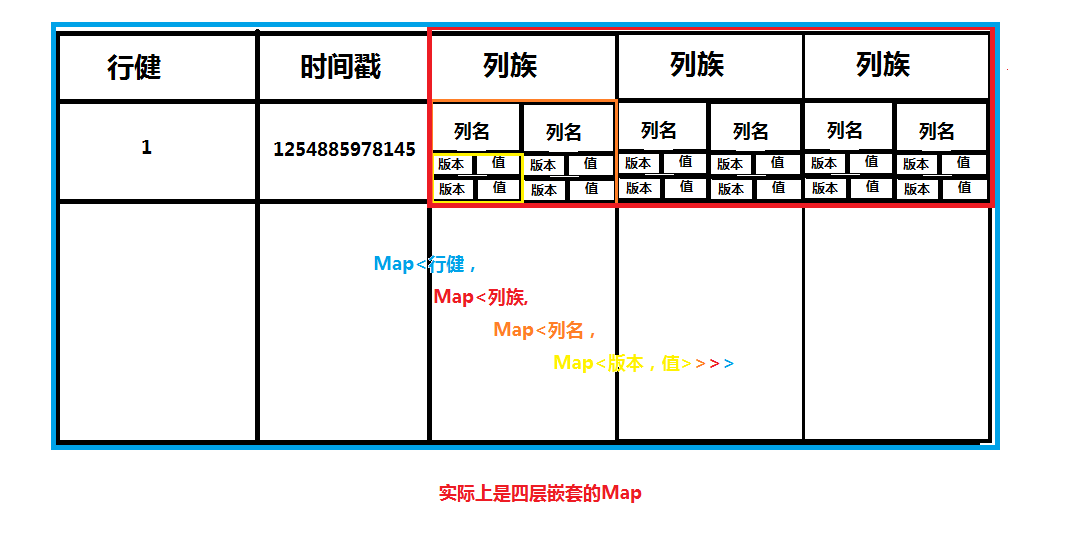
Row Key(行键)
Row Key是用来检索记录的主键,访问HBase中table的行只有以下三种方式:
- 通过完整的Row Key访问
- 通过Row Key的模糊查询(正则)
- 全表扫描
注:Row Key可以是任意字符串,在HBase内部,Row Key会被存储为byte[]。存储数据时,数据会按照Row Key的字典序排序。
Columns Family(列族)
HBase表中的每个列,都归属于某个列族。列族是表结构的一部分(而列不是),必须在使用表之前定义。列名都以列族作为前缀。例如courses:history,courses:math都属于courses这个列族。
Cell
由{row key,columns family}确定的唯一单元,cell中的数据是没有类型的,全部是字节码形式存贮。
Time Stamp
HBase中通过row key和columns family确定的唯一一个存贮单元称为cell。每个 cell都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64位整型。时间戳可以由HBase(在数据写入时自动)赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。每个cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理(包括存贮和索引)负担,Hbase提供 了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段 时间内的版本(比如最近七天)。用户可以针对每个列族进行设置。
HBase原理
- 体系图
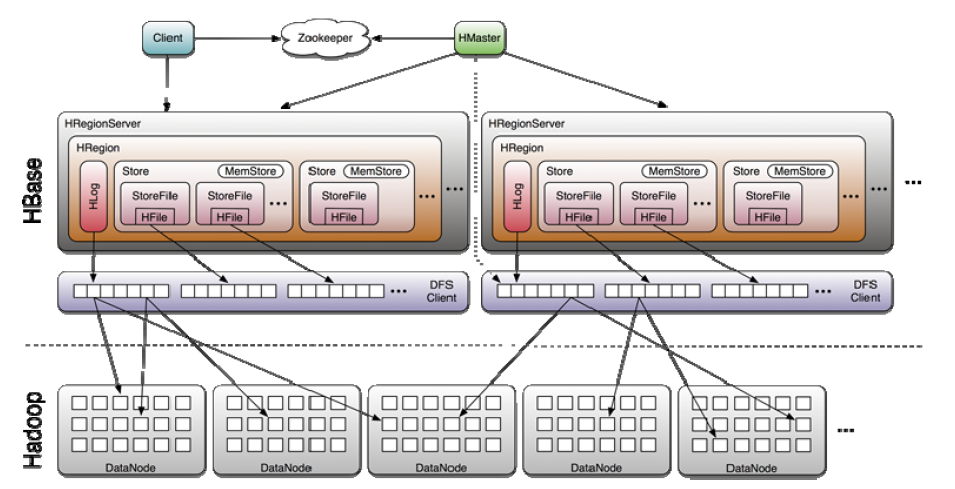
- HBase的读流程
- 通过zookeeper和-ROOT- .META.表定位HRegionServer
- 数据从内存和硬盘合并后返回给client
- 数据块会缓存
- HBase的写流程
- client向HRegionServer发送写请求
- HRegionServer将数据写到hlog(write ahead log)。为了数据的持久化和恢复
- HRegionServer将数据写到内存(memstore)
- 反馈client写成功
- 数据flush过程
- 当memstore数据达到阈值(默认是64M),将数据刷到硬盘,将内存中的数据删除,同时删除hlog中的历史数据
- 将数据存储到hdfs中
- 在hlog中做标记点
- 数据合并操作
- 当数据块达到4块,HMaster将数据块加载到本地,进行合并
- 当合并的数据超过256M,进行拆分,将拆分后的region分配给不同的HRegionServer管理
- 当HRegionServer宕机后,将HRegionServer上的hlog拆分,然后分配给不同的hregionserver加载,修改.META.
- 注意:hlog会同步到hdfs
- HMaster的功能
- 管理用户对Table的增、删、改、查操作
- 记录region在哪台HRegionServer上
- 在Region Split后,负责新Region的分配
- 新机器加入时,管理HRegionServer的负载均衡,调整Region分布
- 在HRegionServer宕机后,负责失效HRegionServer上的Regions迁移
- HRegionServer的功能
- 主要负责响应用户IO请求,向HDFS文件系统中读写数据,是HBASE中最核心的模块。
- HRegionServer管理了很多table的分区,也就是region。
- client的功能
- HBase的Client使用HBase的RPC机制与HMaster和HRegionServer进行通信
- 管理类操作:Client与HMaster进行RPC
- 数据读写类操作:Client与HRegionServer进行RPC
HBase和zookeeper
HBase依赖zookeeper来管理数据信息
- 保存HMaster的地址
- 管理HRegionServer
- 增删改查表的节点
- 管理HRegionServer中表的分配
- 保存表ROOT的地址
HBase默认的根表,检索表 - 管理HRegionServer的列表
- 表的增删改查数据
- 和hdfs交互,存取数据
HBase的shell命令
进入HBase的shell
hbase shell命名空间
- 创建命名空间
create_namespace ‘命名空间名’ - 展示所有的命名空间
list_namespace - 删除命名空间 ‘命名空间名’
drop_namespace ‘命名空间名’
- 创建命名空间
创建表
- 一般表:
create ‘表名’,’列族名1’,’列族名2’… - 指定版本号:
create ‘表名’, {NAME => ‘列族名’, VERSIONS => 最大版本数量},{NAME => ‘列族名2’,VERSIONS => 最大版本数量}… - 预定义分区:
create ‘表名’,{NAME => ‘列族名’, VERSIONS => 最大版本数量},SPLITS => [‘1000’, ‘2000’, ‘3000’, ‘4000’] - 导入文件中的分区规则:
create ‘表名’,’列族名’,{SPLITS_FILE => ‘文件名’} - HexStringSplit算法分区:
create ‘表名’, ‘列族名’, {NUMREGIONS => 分区数量, SPLITALGO => ‘HexStringSplit’}
注:适合散列字符不包含中文,适合16进制的row key或者前缀是16进制的row key - UniformSplit算法分区:
create ‘表名’, ‘列族名’, {NUMREGIONS => 分区数量, SPLITALGO => ‘UniformSplit’}
注:row key可以包含中文,适合随机字节数组的row key
- 一般表:
删除表
- 第一步:disable ‘表名’
- 第二步:drop ‘表名’
修改表结构
- 增加列族:
alter ‘表名’, {NAME => ‘列族’, IN_MEMORY => true}, {NAME => ‘列族’, VERSIONS => 5} - 删除列族:
alter ‘表名’, {METHOD => ‘delete’,NAME => ‘列族’}
- 增加列族:
查看表信息
- 展示所有表
list - 判断表是否存在
exists ‘表名’ - 描述表
desc ‘表名’ - 判断是否禁用表
is_enabled ‘表名’
is_disabled ‘表名’ - 查看表中的记录总数
count ‘表名’
- 展示所有表
添加、修改、删除表数据
- 添加记录
put ‘表名’,’行键’,’列名:列’,’值’ - 删除指定记录
delete ‘表名’,’row key’,’列族:列’ - 删除整行
deleteall ‘表名’,’row key’ - 清空表
truncate ‘表名’ - 修改记录
HBase中没有修改,只要再put数据进行覆盖,相当于修改
- 添加记录
获取数据
- 获取指定row key存储的数据
get ‘表名’,’row key’ - 获取某个列族
get ‘表名’,’row key’,’列族’ - 获取某个列族的某个列
get ‘表名’,’row key’,’列族:列名’ - 获取某列前5个版本的数据
get ‘表名’,’row key’,{COLUMN => ‘列族:列名’,VERSION => 5} - 获取某个时间段的数据,不一定是最新的数据
get ‘表名’, ‘row key’, {TIMERANGE => [时间戳1,时间戳2]}
- 获取指定row key存储的数据
扫描数据(相当于查询)
- 扫描整张表
scan ‘表名’ - 查看某个表中某个列的所有数据
scan ‘表名’,{COLUMNS => ‘列族名:列名’} - 使用limit进行行数的限制
scan ‘表名’,{COLUMNS=>’列族名:列名’,LIMIT=>行数} - 指定从某一行开始扫描
scan ‘表名’,{COLUMNS=>’列族名:列名’,LIMIT=>行数,STARTROW=>’1002’} - 扫描所有数据的前5个版本
scan ‘表名’,{VERSIONS=>5} - 超出版本限制也能访问到
scan ‘表名’,{VERSIONS=>5,RAW=>true} - 使用行键前缀过滤器
scan ‘表名’, {ROWPREFIXFILTER => ‘100’}
注:此处的100为字符串,只返回行键开头是字符串’100’的数据 - 使用空值行键过滤器,只返回行键
scan ‘表名’,{FILTER=>’KeyOnlyFilter()’} - 使用列名前缀过滤器
scan ‘表名’,{FILTER=>”ColumnPrefixFilter(‘na’) “} - 返回行键>=1001的数据
scan ‘表名’,{FILTER=>”RowFilter(>=,’binary:1001’)”} - 使用行键!=1001的数据,binary: 帮助数据类型转化
scan ‘表名’,{FILTER =>”RowFilter(!=,’binary:1001’)”} - 使用列名过滤器
scan ‘表名’,{FILTER =>”QualifierFilter(>=,’binary:baseinfo:name’)”} - 使用子串过滤器
scan ‘表名’,{FILTER =>”ValueFilter(=,’binary:zhao’)”} - 列名前缀过滤器
scan ‘表名’,{FILTER =>”ColumnPrefixFilter(‘name’)”} - 使用多种过滤器进行条件结合
scan ‘表名’,{FILTER =>”( ValueFilter(=,’binary:manager’)) OR (RowFilter (>,’binary:1003’))”} - 使用page过滤器,限制每页展示数量
scan ‘表名’,{FILTER => org.apache.hadoop.hbase.filter.KeyOnlyFilter.new()} - 使用行键过滤器,进行正则表达式的匹配
scan ‘表名’, {FILTER => RowFilter.new(CompareFilter::Com pareOp.valueOf(‘EQUAL’),RegexStringComparator.new(‘.ll.‘))}
- 扫描整张表
最后更新: 2018年11月21日 14:26