简介
Spark是基于内存计算的大数据分布式计算框架。Spark基于内存计算,提供可交互查询方式,提供近实时处理方式,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。
Spark使用Scala语言进行实现,它是一种面向对象、函数式编程语言,能够像操作本地集合对象一样轻松地操作分布式数据集(Scala提供一个称为Actor的并行模型,其中Actor通过它的收件箱来发送和接收非同步信息而不是共享数据,该方式被称为:Shared Nothing模型)。
特点
运行速度快
数据从内存中读取,理论上速度可以高达HadoopMapReduce的100多倍。适用性强
- 支持3种语⾔言的API:scala、java、python,特别是Scala是一种高效、可拓展的语言,能够用简洁的代码处理较为复杂的处理工作。
- 能够读取HDFS、Cassandra和HBase等离线数据。
- 能够读取Kafka、Flume和Kinesis等实时数据。
- 能够以Mesos、YARN或Standalone作为资源管理器调度JOB,进行集群资源的合理分配和容错,来完成Spark应用程序的计算。
通用性强
Spark生态圈即BDAS(伯克利数据分析栈)包含了Spark Core、Spark SQL、MLLib、GraphX、Spark Streaming和Structured Streaming等组件,提供离线计算、实时计算、图形化处理和机器学习等能力,能够无缝的集成并提供一站式解决方案。
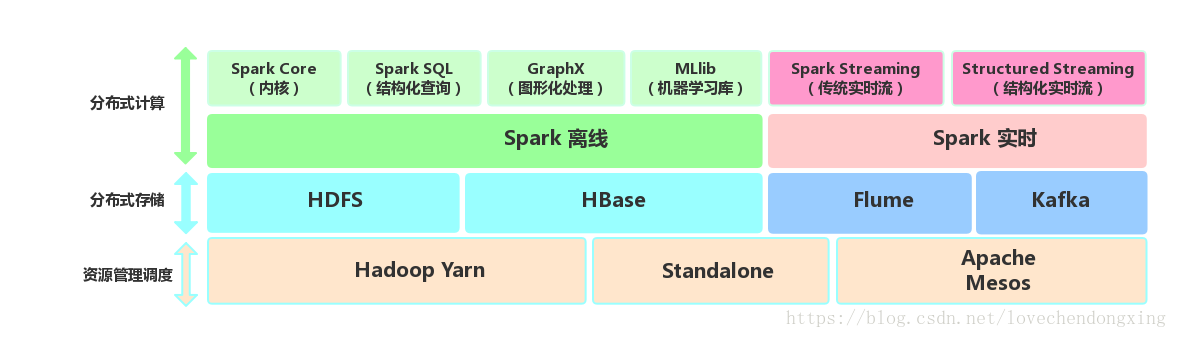
* Spark Core:包含Spark的基本功能。尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的。 * Spark SQL:提供Hive查询语言(HiveQL)以及SQL查询语言(如Mysql)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark Core操作。 * Spark Streaming:对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据。 * Structured Streaming:以结构化的方式操作流式数据,能够像使用Spark SQL处理批处理一样,处理流数据。基于Event-Time,相比于SparkStreaming的Receive-Time更精确。 * GraphX:控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作。 * MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。
Spark和Hadoop的区别
Hadoop有两个核心模块,分布式存储模块HDFS和分布式计算模块MapReduce。
Spark本身并没有提供分布式存储能力,因此Spark的数据存储大多依赖于Hadoop的分布式文件系统HDFS。
Hadoop的MapReduce与Spark都可以进行数据计算,而相比于MapReduce,Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算。官方提供的数据表明,如果数据由磁盘读取,速度是MapReduce的10倍以上,如果数据从内存中读取,速度可以高达100多倍。
Spark的容错性高,通用性好。
Spark的适用场景
- Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小
- 由于RDD的特性,Spark不适用那种异步细粒度更新状态的应用,例如web服务的存储或者是增量的web爬虫和索引。就是对于那种增量修改的应用模型不适合
- 数据量不是特别大,但是要求实时统计分析需求
Spark项目的pom.xml文件
环境:intellij idea 2017.3.4 + maven 3.5.0
pom.xml
最后更新: 2018年11月23日 16:29
原始链接: https://www.lousenjay.top/2018/10/09/Spark入门详解(一)-Spark简介/